
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 가상환경구축
- docker
- __init__
- 딥러닝
- 가상환경
- 파이썬
- tensorflow
- objectdetection
- 머신러닝
- LSTM
- ViT
- torch.nn.Module
- ubuntu
- Torchvision
- 파이썬문법
- rnn
- pytorch
- vision transformer
- __call__
- wsl2
- torch.nn
- AI
- Visual Studio Code
- CNN
- python
- DeepLearning
- Anaconda
- python 문법
- vsC
- pychram
- Today
- Total
인공지능을 좋아하는 곧미남
[Vision Transformer] FC LSTM, ConvLSTM 본문
오늘은 이미지 및 영상을 활용할 수 있는 ConvLSTM을 알아보겠습니다. ConvLSTM은 저번 포스팅에서 설명드린 일반 LSTM이 아닌 FC LSTM 구조에서 Convolution 연산을 적용한 사례로 FC LSTM부터 간단히 알아보도록 하겠습니다.
오늘의 내용은 아래 목차와 같습니다.
< INDEX >
1. FC LSTM 설명
2. ConvLSTM 설명
1. FC LSTM (Fully-Connected Long Short-Term Memory)
FC-LSTM은 LSTM에서 발전한 모델입니다.
구조적으로 변경된 내용이 있는데요.
기존의 LSTM에는 Long Term Memory의 정보를 가진 Cell State의 정보를 Hidden Layer에 사용하지 않았습니다.
하지만, FC-LSTM은 이 Cell State 정보를 Hidden Layer에서 사용하게 되는데요!
- FC-LSTM의 모델 구조와 수식은 아래와 같습니다. -


상당히 복잡해보이지만, Cell State의 정보를 각 Gate에 추가하여 Hidden State를 업데이트하는데 도움을 주는 구조입니다.
그런데 LSTM은 Cell State가 Weight에 직접적인 영향이 없어서 Vanishing Gradient에 좀 더 보완된다는 내용이었다. 그런데 여기서 Cell State가 저런식으로 각 Gate에 투입이 되면 영향이 없을까?
정답은 영향이 없다. 왜냐하면, Ct와 Ct-1 관계를 생각해보면 그 둘은 직접적으로 Weight에 의한 관계가 없다. 따라서, FC LSTM 또한 올바른 접근 방법이라고 할 수 있다.
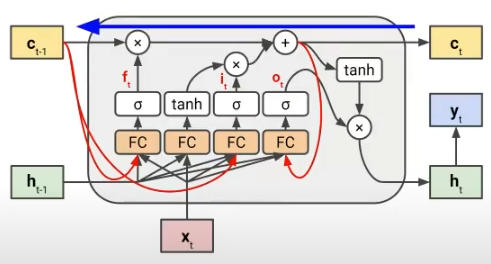
자, 이제 FC LSTM의 설명은 이렇게 마무리하고 오늘의 목적인 ConvLSTM을 설명해보겠습니다.
2. Convolutional LSTM Network
위에 설명한 FC LSTM을 기반으로 Two Dimension의 이미지, 영상의 공간 정보를 학습하기위해 고안되었다.
제가 구현한 convLSTM 코드는 저의 Github을 참고해주십시오. *url: https://github.com/sangheonEN/Vision_Transformer
1. 크게 FC LSTM과 비교해서 두 가지 변화가 있다.
1) Input과 Hidden, Cell State의 Variables이 Vector에서 Matrix로 확장되었다.
2) Weight (Whh, Wxh)가 Vector형식이 아닌 Input에 맞추어 Matrix형식 2D로 하여금 세팅되고 Weight와 Variable이 Convolution 연산이 이루어진다.
- ConvLSTM 모델의 구조 -
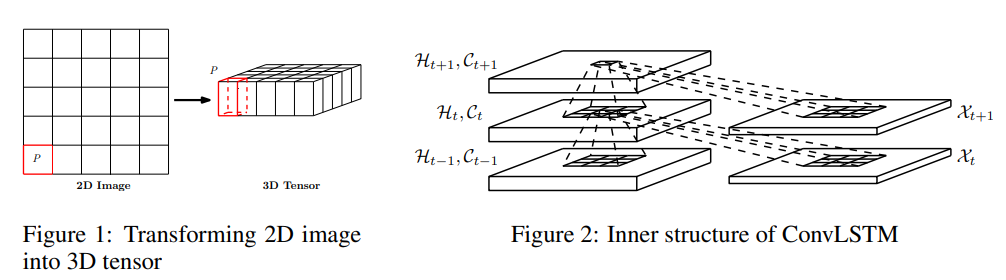

FC-LSTM은 Input to State, State to State 간에 Full Connections으로 인해서 No Spatial Information is encoded.
그래서 Input, Cell, Hidden State, Gate들을 모두 3D Tensors (P, M, N)로 바꾼다.

또한, 각 Weight와 Variable의 연산을 Convlution 연산으로 한다. 근데 여기서 Cell State의 Weight 연산은 그냥 두 행렬의 성분 곱으로 한다.
2. 최종적인 ConvLSTM의 Network는 총 두가지 Network로 구성. (인코딩 Network, 예측 Network)
- ConvLSTM Network (Encoding, Forecasting) -
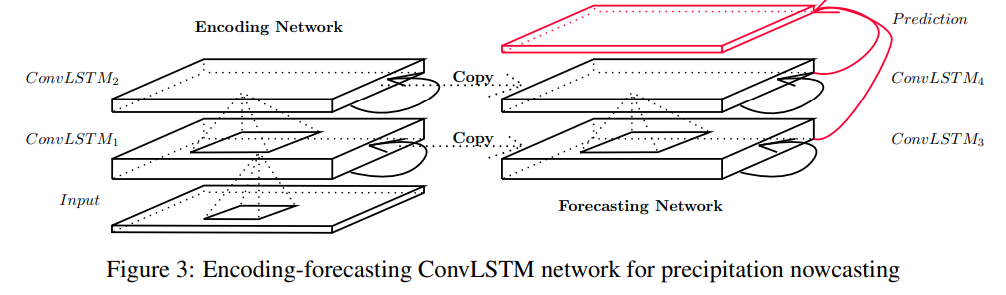
1) Encoding Network: Seq to Seq 알고리즘과 유사하게 Output은 출력하지 않고 Input Frame을 받아서 Hidden Layer에 비디오 정보(Cell State, Hidden State)를 저장한 후 Forecasting Network에 전달한다.
2) Forecasting Network: Encoding Network에서 전달받은 Cell State, Hidden State 정보를 바탕으로 미래 Frame을 예측한다.

- Network는 Multiple Stacked ConvLSTM Layers를 가져서 많은 ConvLSTM Layer층으로 구성된다.
즉, 한줄평으로 ConvLSTM은 이미지나 영상의 공간정보를 같이 학습함으로서 미래의 Frame에서 객체 탐지나 위치 추적이 가능합니다.
ConvLSTM에서는 저 FC LAYER를 Convolution Operation으로 전환하여 연산합니다.
'컴퓨터비전 > Vision Transformer' 카테고리의 다른 글
| [Vision Transformer] RNN, LSTM 이론 (0) | 2022.01.04 |
|---|
