
- 분류 전체보기 (60)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬문법
- objectdetection
- ViT
- AI
- pychram
- __init__
- pytorch
- Torchvision
- LSTM
- __call__
- tensorflow
- git pull
- rnn
- 가상환경구축
- 파이썬
- CNN
- torch.nn.Module
- ubuntu
- Anaconda
- wsl2
- 가상환경
- python
- docker
- DeepLearning
- pip install
- 딥러닝
- vision transformer
- torch.nn
- 머신러닝
- Deep learning
- Today
- Total
인공지능을 좋아하는 곧미남
[Vision Transformer] RNN, LSTM 이론 본문
오늘은 딥러닝에 적용할 수 있는 순환구조를 이해하기 위한 RNN, LSTM 이론을 알아보겠습니다.
1. RNN-순환신경망 (Recurrent Neural Network)
1) RNN 순환구조: RNN의 순환구조를 이해하기 편하게 아래 그림을 빗대어 설명하면,

RNN CELL은 초록색의 상자로 표현되는데, 첫번째 INPUT X1를 받아와 Hidden State인 RNN CELL을 업데이트하고 Y1을 출력하고 그 다음 시퀀스(i=2)의 Hidden State RNN CELL에 정보가 전달된다. 이 과정을 마지막 시퀀스까지 반복하는 것이 RNN의 순환구조이다. (여기서 Output은 Many to Many, Many to One Task에 따라 다르고 출력하고 싶은 시점의 출력을 얻을 수 있다.)
수학적 Fomulation, 새로운 Hidden State(ht)는 그 전 단계의 Hidden State(ht-1)과 현재 입력 Xt 정보로 표현

2) RNN 순환구조에서 가지는 Weight은 아래의 수식과 같은데요. Whh는 ht-1이 ht에 전달되는 weight를 나타내고 Wxh는 Xt가 ht에 전달되는 weight를 나타냅니다. 따라서, 각 입력과 weight를 곱한 vector의 합을 tanh()를 적용한 것이 다음 단계의 hidden state가 된다.
tanh()를 사용함으로서 nonlinearlity하는 이유!
선형 함수인 h(x)=cx, h(x)=cx를 활성 함수로 사용한 3층 네트워크를 떠올려 보세요. 이를 식으로 나타내면 y(x)=h(h(h(x)))가 됩니다. 이 계산은 y(x)=c∗c∗c∗x처럼 세번의 곱셈을 수행하지만 실은 y(x)=ax와 똑같은 식입니다. a=c3이라고만 하면 끝이죠. 즉 히든레이어가 없는 네트워크로 표현할 수 있습니다. 그래서 층을 쌓는 혜택을 얻고 싶다면 활성함수로는 반드시 비선형함수를 사용해야 합니다.

3) RNN이 구현되는 대표적인 Case
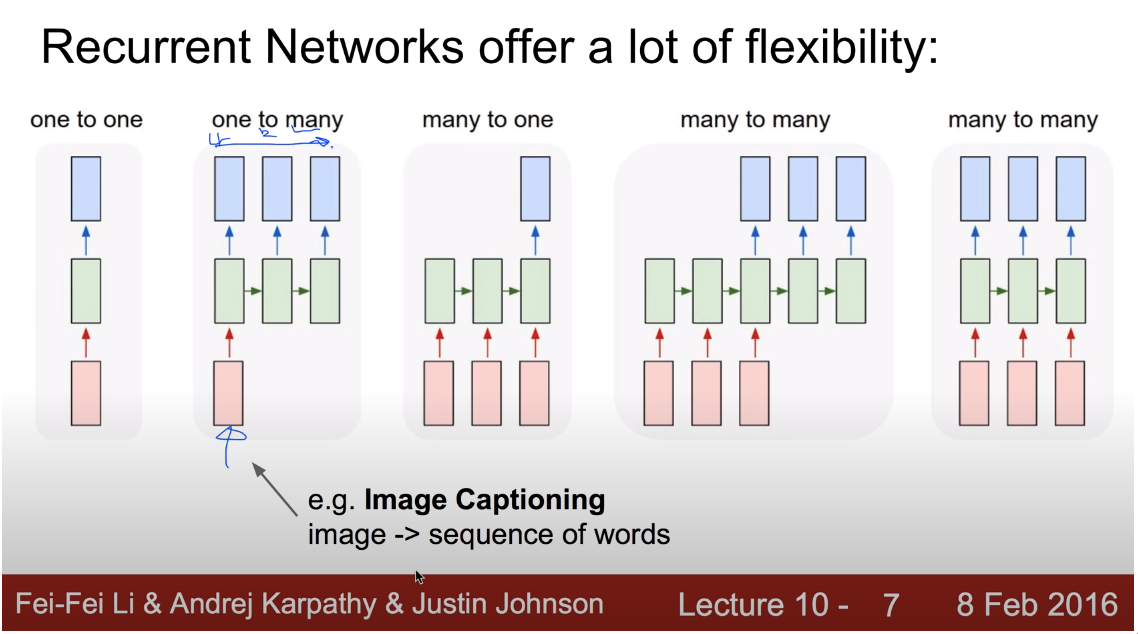
4) Loss Function으로 weight가 업데이트되는 과정 (Training 과정). 학습 시 시퀀스가 진행되면서 각 시점마다 Whh, Wxh가 업데이트 되고 마지막 Hidden State(h)에서 Output(y)로 보내지는 Why가 parameter로 되어 . 물론 weight가 업데이트 되는 시점은 Output이 출력되어 GT와 비교하여 Loss Function이 계산되고 나서다.
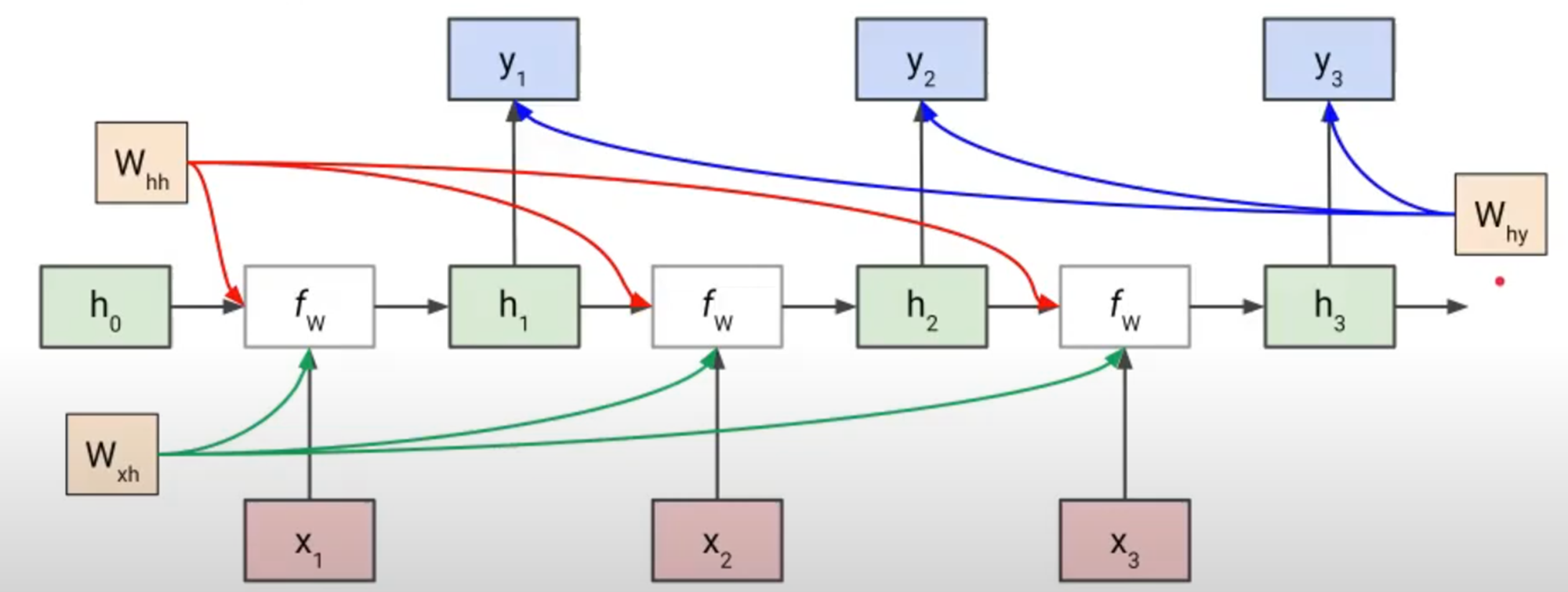
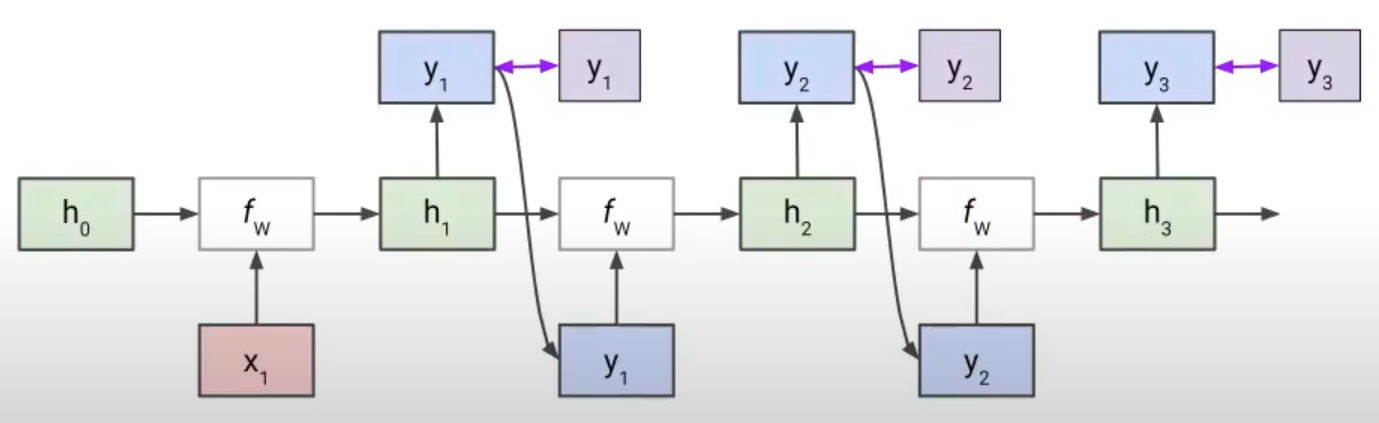
그러면, 위 사진은 모든 스퀀스마다 입력과 출력이 있기 때문에 이해가 쉽지만, One to Many인 경우엔 다음 시퀀스의 입력이 없다. 그러면 어떻게 구현해야할까?
5) One to Many 구현 방법: 그 전단계의 output을 다음 단계의 input으로 전달하여 진행함. (Autoregressive)
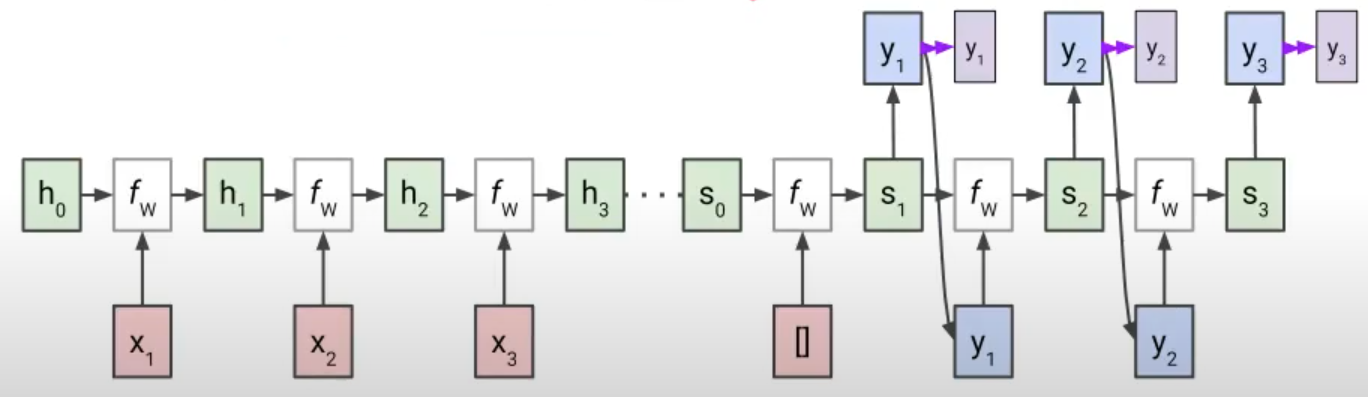
6) 복잡한 Many to Many 구현 방법: Many to Many라고 하더라도 input이 모두 주어지지 않고 output의 출력 시퀀스가 같지 않을 때 복잡한 구조가 될 수 있다. 그러면, 처음부터 마지막 input 시퀀스까지는 output을 출력하지 않고 hidden state, input weight만 업데이트하다가 마지막 input을 입력한 뒤 위와 같이 그 시점의 output을 다음 단계의 input으로 하여 구현한다. 이 과정을 Seq to Seq(시퀀스 투 시퀀스)라고 명칭한다.
6) RNN 장점 및 단점
- 장점
- Input의 길이에 제한을 받지 않는다.
- 현재 상태 뿐만아니라 이전 상태의 정보를 활용할 수 있다. (이론상으로)
- 단점:
- 순차적으로 학습이 이루어지기 때문에 Parallelized가 잘 되지 않고 학습 시간이 길다.
- 현실적으로 Long-Range Dependence가 실패해 Vanishing Gradient가 발생. ->LSTM이 고안된 이유
2. LSTM (Long Short-Term Memory)
RNN의 Long-Range Dependence가 실패함으로서 Vanishing Gradient가 발생하는 것을 좀 더 보완해주고자 고안된 논문이 LSTM이다.
간단히 설명하면, Hidden Layer 내에 여러가지 Gate들을 생성하여 이전의 short term 정보(ht-1), input의 정보(Xt), Long Term 정보(Ct)를 얼마나 다음 short term 정보에 영향을 미치게 할 것인지 정해주는 로직을 만들었다.
LSTM 구조 그림을 보면, 기존의 RNN 구조에서 3가지 Gate(f, i, o)와 Cell State(C) 추가 되었다.
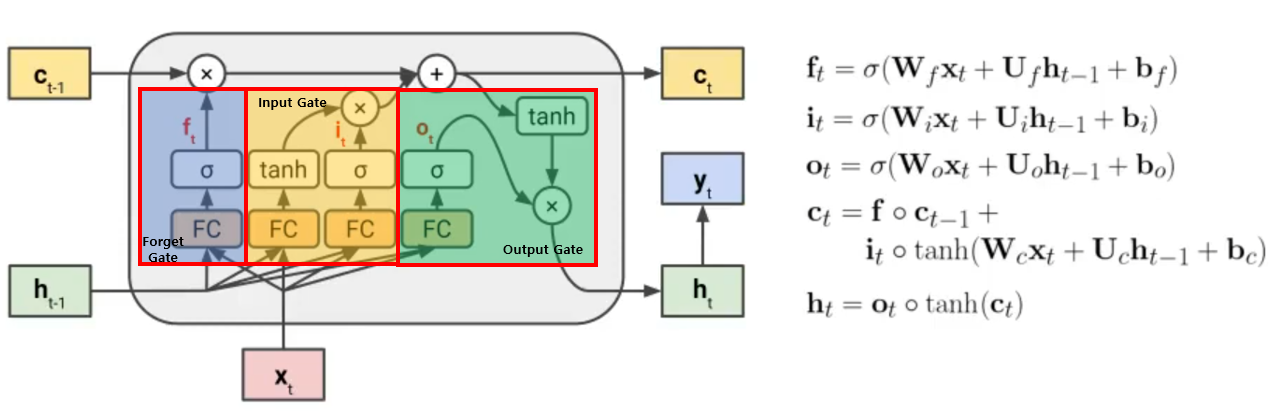
- Hidden State (h): Vanishing Gradient 발생하기 때문에, Long Term보다는 Short Term Memory의 정보를 전달한다.
- Cell State (c): 직접적으로 weight가 곱해지지 않는 State로 Long Term Memory의 정보를 전달한다.
- Forget Gate (f): Long Term Memory의 정보를 이후의 시퀀스로 얼마나 전달할지 정한다.
- Input Gate (i): 새로운 Input Xt에 관한 정보를 얼마나 주입할지 정한다.
- Output Gate (o): Long Term Memory의 정보가 다음 시퀀스의 Short Term Memory 정보에 얼마나 영향을 미칠지 정한다.
* ht-1과 Xt의 정보를 받는 것이 Fully Connected Layer로 표현되었고, 그 값을 시그모이드를 취하면 0 ~ 1사이의 값이 출력된다. 0에 가까울수록 정보의 전달량은 줄어들고 1에 가까울수록 정보의 전달량을 커진다고 볼 수 있다.
해당 게시물은 아래 자료들을 참고하여 만들었습니다.
참고문헌
1. https://www.youtube.com/watch?v=mDcz8wD2a7Y&list=PL0E_1UqNACXD5trR4II4ltJ0dBBt0ztTV&index=21
1) 순환 신경망(Recurrent Neural Network, RNN)
RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델입니다. 번역기를 생각해보면 입력은 번역하고자 하는 ...
wikidocs.net
3. https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
'컴퓨터비전 > Vision Transformer' 카테고리의 다른 글
| [Vision Transformer] FC LSTM, ConvLSTM (0) | 2022.01.04 |
|---|
